子模块说明¶
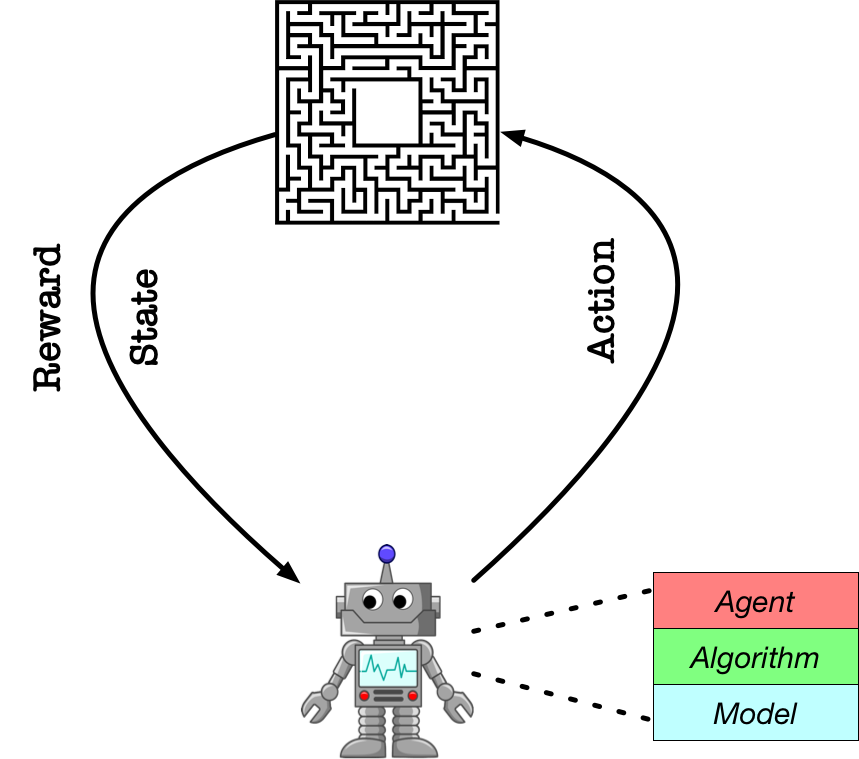
在上一个教程中,我们快速地展示了如果通过PARL的三个基础模块:Model , Algorithm , Agent 来搭建智能体和环境进行交互的。在这个教程中,我们将详细介绍每个模块的具体定位,以及使用规范。
Model¶
定义:
Model用来定义前向(Forward)网络,这通常是一个策略网络(Policy Network)或者一个值函数网络(Value Function),输入是当前环境状态(State)。⚠️注意事项:用户得要继承
parl.Model这个类来构建自己的Model。- 需要实现的函数:
forward: 根据在初始化函数中声明的计算层来搭建前向网络。
备注:在PARL中,实现强化学习常用的target network很方便的,直接调用
copy.deepcopy即可。示例:
import paddle
import paddle.nn as nn
import parl
import copy
class CartpoleModel(parl.Model):
def __init__(self, obs_dim, act_dim):
super(CartpoleModel, self).__init__()
hid1_size = act_dim * 10
self.fc1 = nn.Linear(obs_dim, hid1_size)
self.fc2 = nn.Linear(hid1_size, act_dim)
self.tanh = nn.Tanh()
self.softmax = nn.Softmax()
def forward(self, x):
out = self.tanh(self.fc1(x))
prob = self.softmax(self.fc2(out))
return prob
if __name__ == '__main__:
model = CartpoleModel()
target_model = copy.deepcopy(model)
Algorithm¶
定义:
Algorithm定义了具体的算法来更新前向网络(Model),也就是通过定义损失函数来更新Model。一个Algorithm包含至少一个Model。⚠️注意事项:一般不自己开发,推荐直接import 仓库中已经实现好的算法。
- 需要实现的函数:
learn: 根据训练数据(观测量和输入的reward),定义损失函数,用于更新Model中的参数。predict: 根据当前的观测量,给出动作概率分布或者Q函数的预估值。
示例:
model = CartpoleModel(act_dim=2)
algorithm = parl.algorithms.PolicyGradient(model, lr=1e-3)
Agent¶
定义:
Agent负责算法与环境的交互,在交互过程中把生成的数据提供给Algorithm来更新模型(Model),数据的预处理流程也一般定义在这里。⚠️注意事项:需要继承
parl.Agent来使用,要在构造函数中调用父类的构造函数。- 需要实现的函数:
learn: 根据训练数据(观测量和输入的reward),定义损失函数,用于更新Model中的参数。predict: 根据环境状态返回预测动作(action),一般用于评估和部署agent。sample:根据环境状态返回动作(action),一般用于训练时候采样action进行探索。
示例:
class CartpoleAgent(parl.Agent):
def __init__(self, algorithm):
super(CartpoleAgent, self).__init__(algorithm)
def sample(self, obs):
obs = paddle.to_tensor(obs, dtype='float32')
prob = self.alg.predict(obs)
prob = prob.numpy()
act = np.random.choice(len(prob), 1, p=prob)[0]
return act
def predict(self, obs):
obs = paddle.to_tensor(obs, dtype='float32')
prob = self.alg.predict(obs)
act = prob.argmax().numpy()[0]
return act
def learn(self, obs, act, reward):
act = np.expand_dims(act, axis=-1)
reward = np.expand_dims(reward, axis=-1)
obs = paddle.to_tensor(obs, dtype='float32')
act = paddle.to_tensor(act, dtype='int32')
reward = paddle.to_tensor(reward, dtype='float32')
loss = self.alg.learn(obs, act, reward)
return loss.numpy()[0]
if __name__ == '__main__':
model = CartpoleModel()
alg = parl.algorithms.PolicyGradient(model, lr=1e-3)
agent = CartpoleAgent(alg, obs_dim=4, act_dim=2)